SDK Introduction
This document describes the development of server instrumentation for YANG data models, using the YumaPro SDK programming environment.
Any YANG model not already implemented by the server can be added by a vendor to the server.
YANG data models are loaded into the server individually or in pre-defined bundles.
The server will automatically support the syntax and protocol mechanics from information in the YANG modules.
The SDK allows YANG model instrumentation to be added to the netconfd-pro server by a developer.
The semantics of the YANG models must be implemented by the developer.
The module-specific functionality comes from the underlying system, not the server.
System interfaces, system resource management, and "description statement" semantics are not automatically implemented by the server.
This instrumentation code is the boundary between the YANG model and the implementation-specific system.
The YumaPro Tools suite provides automated support for development and usage of network management information.
Terminology
Data Tree
The Data Tree is a representation of some subset of all possible object instances that a server is maintaining within a configuration database or other structure.
Each Data Tree starts with a Root container, and any child nodes represent top-level YANG module data nodes that exist within the server.
This definition is consistent with the term "data tree" defined in RFC 7950.
Object Tree
The Object Tree is a tree representation of all the YANG module RPC, data definition, and notification statements. It starts with a Root container. This is defined with a YANG container statement which has an ncx:root extension statement within it.
The <config> parameter within the <edit-config> operation is an example of an object node which is treated as a Root container. Each configuration database maintained by the server (E.g., <candidate> and <running>) has a Root container value node as its top-level object.
This is also called a "schema tree" in RFC 7950, but that is a more restrictive term than used here.
Root Container
The Root container is defined with a YANG container statement which has an ncx:root extension statement within it. The Root container does not have any child nodes defined in it within the YANG file. However, the YumaPro tools will treat this special container as if any top-level YANG data node is allowed to be a child node of the Root container type.
Schema Tree
The Schema Tree is a conceptual set of schema nodes derived from all YANG modules that a server is maintaining within a configuration database or other structure.
Each Schema Tree starts with a Root container, and any child nodes represent top-level YANG module data nodes that exist within the server.
The ncx:root extension is used to identify a YANG object that is being used as a root node of a schema tree.
This definition is consistent with the term "schema tree" defined in RFC 7950.
Server
Usually refers to software running in the netconfd-pro process.
Sometimes refers to the entire server, including all subsystems.
SIL
Server Instrumentation Library
Usually YANG module or bundle specific
Executed in the netconfd-pro process
Contains the 'glue code' that binds YANG content (managed by the netconfd-pro server), to a platform (networking device)
SIL-SA
Server Instrumentation Library : Sub Agent
Implicitly YANG module or bundle specific
Executed on a Subsystem
PY-SIL
Python version of Server Instrumentation Library : Sub Agent
Implicitly YANG module or bundle specific
Executed on a Subsystem
Subsystem
Refers to YControl Subsystem
Usually limited to one of
SIL-SA,DB-API, orYP-HA
API Overview
API Map
YumaPro tools provide numerous APIs that can be used to effectively perform desired tasks, improve efficiency, refine auto-generated code, and extend default functionality.
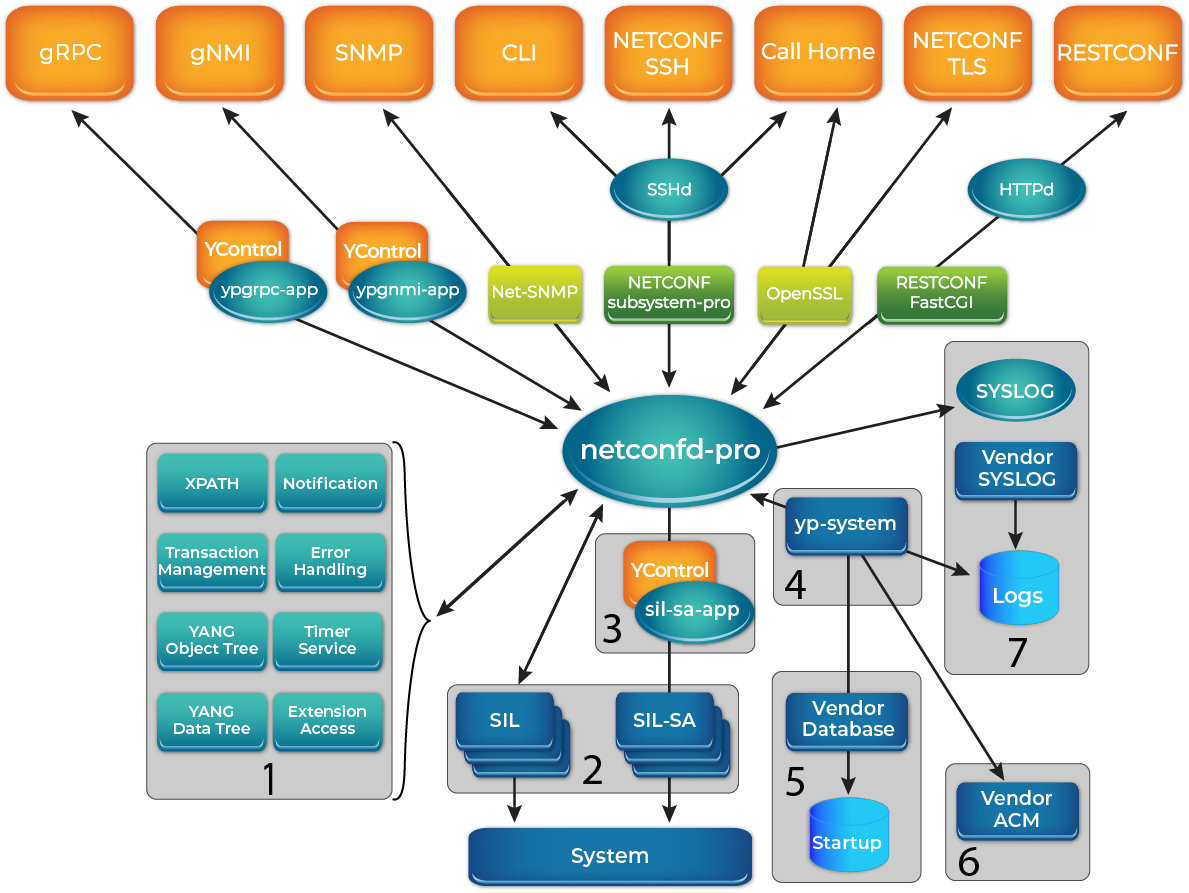
YumaPro netconfd-pro API map key:
(1) Utility APIs
Notification functions provide control over notifications.
XPATH Handling/Validation functions can be used to manipulate XPATH expressions.
Error Handling functions provide various alternative ways to record an error.
Transaction Management functions provide control on the transaction and can be invoked within, before, and after the transaction.
Timer Service functions allow some SIL code that may need to be called at periodic intervals to check system status, update counters, and/or send notifications.
Object Tree manipulation functions let you retrieve object properties without accessing them directly.
Extension Access functions allow to manipulate with custom YANG extensions.
YANG Data Tree manipulation functions provide access functions to the data nodes.
(2) Server Instrumentation Library (SIL) Utility Functions
Provide control on SIL libraries and allows them to be used more efficiently.
(3) YControl and DB-API Interface Functions
Provide control on subsystem and DB-API interfaces.
(4) System Callback Functions
Allow the creation and use of general system SIL libraries.
(5) Database Access Functions
Allow validation, manipulation, and management of the configuration database.
(6) Access Control Functions
Allow configuration and enforcement of a vendor specific access control model (ACM).
(7) SYSLOG and Log Functions
Allow customized logging interface and preferences.
API Types
The YumaPro SDK provides several types of server APIs:
Transaction Management
Functions that provide control on the transaction and can be invoked within, before, and after the transaction.
Object Tree Manipulation
Functions to access the YANG Schema Tree
YANG Data Tree Manipulation
Functions that provide access functions to YANG data nodes within the NETCONF datastores.
Error Handling
Functions provide various alternative ways to record an error.
Notification Delivery
Functions to provide control of notifications.
Event Stream Callbacks
Provide info on whether any clients are listening to an event stream.
XPATH Handling/Validation
Functions can be used to manipulate XPATH expressions.
YANG Extension Access
Functions to allow to manipulate with custom YANG extensions.
Timer Service
Functions to allow SIL code to be called at periodic intervals to check system status, update counters, and/or perhaps send notifications.
SIL Utility
Functions to provide control on SIL libraries and allows to use them more efficiently.
System Callback
Functions allow to creating and use the general system library, not specific to one YANG module or bundle.
Access Control
Functions to allow to configure and enforce client permissions for YANG-based protocol access.
SYSLOG and Log Control
Functions to allow to customize logging.
Support for Linux SYSLOG or Vendor SYSLOG
Database Access
Functions to validate, manipulate, and manage the configuration data.
YCONTROL Interface
Functions to provide communication service between sub-agents and the main server.
DB-API Interface
Provides database interface functions to edit the internal database from another internal process.
Warning
YUMAWORKS RESERVES THE RIGHT TO CHANGE INTERNAL DATA STRUCTURES AT ANY TIME WITHOUT NOTICE! API FUNCTIONS ARE STABLE, NOT DATA STRUCTURES!
API Services
All of the major server functions are supported by service layers in the 'agt' or 'ncx' libraries:
Memory Management
Macros in
platform/procdefs.hare used instead of using direct heap functions.The macros 'm__getMem' or 'm__getObj' are used by YumaPro code to allocate memory.
Both of these functions increment a global counter called 'malloc_count'.
The macro 'm__free' is used to delete all malloced memory.
This macro increments a global counter called 'free_count'.
When a YumaPro program exits, it checks if 'malloc_count' equals 'free_count', and if not, generates an error message. If this occurs, the
MEMTRACE=1parameter can be added to the make command to activate 'mtrace' debugging.
Queue Management
APIs in
ncx/dlq.hare used for all double-linked queue management.
XML Namespace Management
XML namespaces (including YANG module namespaces) are managed with functions in
ncx/xmlns.h.An internal "namespace ID" is used internally instead of the actual URI.
XML and JSON Parsing
XML and JSON input processing data structures and functions can be found in
ncx/xml_util.h
XML and JSON Message Processing
XML and JSON message support (data structures and functions) can be found in
ncx/xml_msg.h
XML and JSON Message Generation with Access Control
XML message generation is controlled through API functions located in
ncx/xml_wr.h.High level (value tree output) and low-level (individual tag output) XML output functions are provided, which hide all namespace, indentation, and other details.
Access control is integrated into XML message output to enforce the configured data access policies uniformly for all RPC operations and notifications.
The access control model is built-in and cannot be bypassed by any vendor-provided server instrumentation code.
XPath Services
All NETCONF XPath filtering, and all YANG XPath-based constraint validation, is handled with common data structures and API functions.
The XPath 1.0 implementation is native to the server, and uses the object and value trees directly to generate XPath results for NETCONF and YANG purposes.
NETCONF uses XPath differently than XSLT, and libxml2 XPath processing can be memory intensive. These functions are located in
ncx/xpath.h,ncx/xpath1.h, andncx/xpath_yang.h.XPath filtered <get> responses are generated in
agt/agt_xpath.c.
Logging Service
Encapsulates server output to a log file or to the standard output, filtered by a configurable log level.
Located in
ncx/log.h.The macro SET_ERROR in
ncx/status.his used to report programming errors to the log.
Session Management
All server activity is associated with a session.
The session control block and API functions are located in
ncx/ses.h.All input, output, access control, and protocol operation support is controlled through the session control block (ses_cb_t).
Timer Service
A periodic timer service is available to SIL modules for performing background maintenance within the main service loop.
These functions are located in
agt/agt_timer.h.
Connection Management
All TCP connections to the netconfd-pro server are controlled through a main service loop, located in
agt/agt_ncxserver.c.The default netconfd-pro server actually listens for local <ncx-connect> connections on an AF_LOCAL socket.
The openSSH server listens for connections on port 830 (or other configured TCP ports), and the netconf-subsystem-pro thin client acts as a conduit between the SSH server and the server.
Database Management
All configuration databases use a common configuration template, defined in
ncx/cfg.h.Locking and other generic database functions are handled in this module.
The actual manipulation of the value tree is handled by API functions in
ncx/val.hncx/val_util.hagt/agt_val_parse.hagt/agt_val.hagt/agt_child.h
NETCONF Operations
Most standard NETCONF RPC callback functions are located in
agt/agt_ncx.c.All operations are completely automated, so these operations cannot be replaced by vendor instrumentation.
NETCONF Request Processing
All <rpc> requests and replies use common data structures and APIs, found in
ncx/rpc.handagt/agt_rpc.h.Automated reply generation, automatic filter processing, and message state data is contained in the RPC message control block.
NETCONF Error Reporting
All <rpc-error> elements use common data structures defined in
ncx/rpc_err.handagt/agt_rpcerr.h.Most errors are handled automatically, but 'description statement' semantics need to be enforced by the SIL callback functions.
These functions use the API functions in
agt/agt_util.h(such as agt_record_error) to generate data structures that will be translated to the proper <rpc-error> contents when a reply is sent.
YANG Library Management
All YANG modules are loaded into a common data structure (ncx_module_t) located in
ncx/ncxtypes.h.The API functions in
ncx/ncxmod.h(such as 'ncxmod_load_module') are used to locate YANG modules, parse them, and store the internal data structures in a central library.
Availability Monitoring Service
The ypwatcher is a program that provides monitoring mechanism to netconfd-pro process and its state.
The ypwatcher program periodically checks the server state to determine if the server is still running.
If the server is no longer running it cleans up the state, restarts the server, and generates a syslog message.
YumaPro Doxygen Browser
The YumaPro server code now supports doxygen. The H files in the 20.10 release train have been redone so they conform to the appropriate doxygen and markdown commands. The HTML generation is supported.
The doxygen output is available online and can also be generated on a local machine if an SDK package or source code package is installed.
The SIL and SIL-SA code generated by yangdump-pro now has built-in doxygen browser support.
It is strongly recommended that the browser be used to learn the APIs and access additional technical support resources.
The doxygen program is a widely available open-source program for generating source code documentation.
Doxygen Home Page:
Online Version
The output for the latest YumaPro release is available online
Local Version
If the source code or a binary SDK package is installed, then the doxygen browser can be built and viewed is a browser as a file. The following scripts now support doxygen output.
The following message is printed after the script runs, showing the steps needed to access the local doxygen browser. (E.g. module
> make_sil_dir_pro test
. . .
Run the following commands to get started:
cd test
make doc
make opendoc
>
The doxygen files can be generated after this step is done.
The URL can also be access locally. The “index.html” file will be in the directory “output/html” under the module root created (E.g. “test” in this example).
Install doxygen
This step is not required to generate any server source code. It is only required to use doxygen.
The doxygen and graphviz packages are used to generate all the doxygen documentation, from your source code and the installed YumaPro H files.
These programs are usually already installed, but if not then try these commands:
Ubuntu:
sudo apt-get install doxygen graphviz
Fedora:
sudo dnf install doxygen graphviz
Centos:
sudo dnf --enablerepo=powertools install doxygen graphviz
Doxygen Group Structure
Doxygen uses a simple hierarchy to create the ‘Modules’ section of the WEB pages for the source code.
This hierarchy is hard-wired at this time.
The top-level group is called “yang-library” and the brief description is simply “YANG Library”.
The “ingroup” command for the auto-generated code will use this value
The 2nd-level group depends on the code that is being generated. There are parts to the group name
“sil-” or “silsa-” depending on code for SIL or SIL-SA
module name or bundle name
If the generated source file is for a module within a bundle, then there will be a 3rd level of grouping.
Each module will have a grouping within the bundle grouping
Example tree for SIL code for “module1”
+-- yang-library
+
|
+-- sil-module1
Example tree for SIL-SA code for “bundle1”
+-- yang-library
+
|
+-- silsa-bundle1
Example tree for SIL-SA code for “module1” and “module2” within “bundle1”
+-- yang-library
+
|
+-- silsa-bundle1
+
|
+ silsa-bundle1-module1
+ silsa-bundle1-module2
Example Doxygen Headers
New GET2 callback for interface statistics:
/**
* @brief Get database object callback for container statistics (getcb_fn2_t)\n
* Path: container /interfaces/interface/statistics\n
*
* Fill in 'get2cb' response fields.
*
* @param get2cb GET2 control block for the callback.
* @param k_if_name Ancestor key leaf 'name' in list 'interface'\n
* Path: /if:interfaces/if:interface/if:name
* @return return status of the callback.
*/
extern status_t u_if_statistics_get (
getcb_get2_t *get2cb,
const xmlChar *k_if_name);
New EDIT2 callback for interface:
/**
* @brief Edit database object callback (agt_cb_fn_t)\n
* Path: list /interfaces/interface
*
* @param scb session control block making the request
* @param msg message in progress for this edit request
* @param cbtyp callback type for this callback
* @param editop the parent edit-config operation type,
* which is also used for all other callbacks
* that operate on objects.
* @param newval container object holding the proposed changes
* to apply to the current config, depending on
* the editop value. Will not be NULL.
* @param curval current container values from the "<running>"
* or "<candidate>" configuration, if any. Could be NULL
* for create and other operations.
* @param k_if_name Local key leaf 'name' in list 'interface'\n
* Path: /if:interfaces/if:interface/if:name
* @return return status for the phase.
*/
extern status_t u_if_interface_edit (
ses_cb_t *scb,
rpc_msg_t *msg,
agt_cbtyp_t cbtyp,
op_editop_t editop,
val_value_t *newval,
val_value_t *curval,
const xmlChar *k_if_name);