Troubleshooting
This section addresses common problems that can occur using the server.
Session Connection Issues
Note
Symptom: Client cannot start a session with the server
Client connection issues depend on the protocol.
netconfd-pro Server Startup Issues
If the server exits during startup, clients may report connection failures because netconfd-pro is not running.
Server exits with top-level mandatory objects error
Some YANG modules define top-level mandatory configuration nodes. When such a module is loaded, mandatory configuration data must be present or the <running> configuration datastore is not valid. The server reports this as error 384 ("top level mandatory objects are not allowed") and exits.
Example:
netconfd-pro --module=ietf-syslog
Starting netconfd-pro...
...
Warning: sil code for module 'ietf-syslog' not found
Error: top-level NP container 'syslog' is mandatory
ietf-syslog.yang:230.3: error(384): top-level mandatory objects are not allowed
Load module 'ietf-syslog' failed (top-level mandatory objects are not allowed)
Error: server exit due to init2 error (top-level mandatory objects are not allowed)
netconfd-pro: init returned (top-level mandatory objects are not allowed)
The same condition is only a warning in the YANG compiler because server instrumentation can populate mandatory nodes during the boot-up phase:
yangdump-pro ietf-syslog
Example output:
Warning: top-level NP container 'syslog' is mandatory
ietf-syslog.yang:230.3: warning(1048): top-level object is mandatory
*** /path/to/modules/ietf-syslog.yang
*** 0 Errors, 1 Warnings
Preferred: Avoid top-level mandatory configuration nodes (update the YANG module).
To allow the server to start and ignore the error, use the --running-error=continue and --startup-error=continue parameters.
This allows startup and running configuration validation to fail at boot time. The operator can then provide the missing mandatory nodes using NETCONF or RESTCONF edit operations.
Add these parameters to the normal server startup command. For example:
netconfd-pro --module=ietf-syslog --running-error=continue --startup-error=continue
If modules are loaded from the netconfd-pro conf file, the --module parameter is not required.
Server exits with unknown parameter error
If the server fails to start with an "unknown parameter" error, a common cause is an invalid command line parameter.
Not Acceptable Character
If the log contains an empty parameter name, some characters in the parameter are not acceptable:
Incorrect example (contains a long dash character "–", not two hyphens "--"):
netconfd-pro –fileloc-fhs=true
Example output:
Error: Unknown parameter ()
netconfd-pro: init returned (unknown parameter)
In this case, verify that the parameter prefix uses ASCII hyphen characters. In some copy/paste workflows, the double hyphen prefix can be replaced with a Unicode long dash character.
Accepted parameter prefix forms:
--fileloc-fhs=true
-fileloc-fhs=true
fileloc-fhs=true
Correct example:
netconfd-pro --fileloc-fhs=true
Unknown Parameter Name
If the log contains a parameter name, that name is not recognized:
netconfd-pro --fileloc-fhs-invalid=true
Error: Unknown parameter (fileloc-fhs-invalid)
netconfd-pro: init returned (unknown parameter)
In this case, confirm that the parameter name is valid for the installed server.
Not Supported Parameter
An older server release may not support a newer parameter. To check whether a parameter is supported, refer to the built-in help or manual page:
netconfd-pro --help
man netconfd-pro
Server exits with unknown-namespace after restart
If a module is loaded dynamically using <load> or <load-bundle>, that module load is not persisted in the server configuration file. If configuration data is created for that module and then the server is restarted, the startup configuration may contain nodes from a YANG module that is not loaded at boot time. In that case, an "unknown-namespace" error can be reported during startup and the server may exit.
Example sequence in a yangcli-pro session:
load toaster
mgrload toaster
create /toaster
commit
restart
Example error:
RPC Error 229:
rpc-error: (229) unknown-namespace L:protocol S:error app-tag:data-invalid lang:en
msg:unknown namespace
error-info: bad-element T:string = --:toaster
error-info: bad-namespace T:string = http://netconfcentral.org/ns/toaster
error-info: error-number T:uint32 = 229
To resolve the issue, make sure the server loads the missing module at boot time (for example, "toaster"), using --module or the netconfd-pro configuration file.
netconfd-pro --module=toaster
If the module still is not found at startup, check the module search path:
The default value for $YUMAPRO_MODPATH is /usr/share/yumapro/modules.
Server cannot start after a crash or debugger exit
If netconfd-pro crashes or is terminated in a debugger without a clean shutdown, stale runtime files can be left behind. On the next start, netconfd-pro may report that it is already running, or fail to create the PID file.
Example error:
Error: program netconfd-pro appears to be running as PID 13342
Error: Cannot create PID file
*** If no other instances of netconfd-pro are running,
*** try deleting /tmp/ncxserver.sock and $HOME/.yumapro/netconfd-pro.pid
*** > rm /tmp/ncxserver.sock
*** > rm $HOME/.yumapro/netconfd-pro.pid
netconfd-pro: init returned (operation failed)
Server Cleanup Starting...
If no other netconfd-pro instance is running, remove the stale runtime files:
rm -f /tmp/ncxserver.sock
rm -f /tmp/netconfd-pro-subsys-info.txt
rm -f $HOME/.yumapro/netconfd-pro.pid
Multi-instance mode can use different socket and PID file locations. Refer to Multi-Instance Mode.
SSH Connection Issues
If a client session is using the SSH server, then this may need to be checked first. This affects protocols:
CLI over SSH
NETCONF over SSH
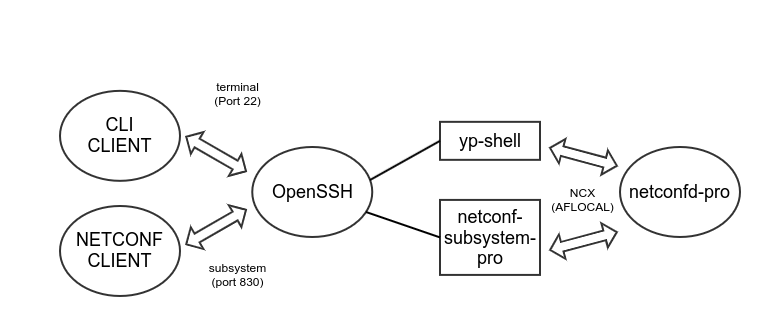
If there is no 'debug' log activity in the netconfd-pro program when the client session is attempted, then the session request is not reaching the NETCONF server. If there is log activity related to the client session, then skip ahead to the Check Server Restricting New Sessions section.
Check the Client Parameters
If a 'connection refused' message is given in the client, then make sure the host and port parameters used by the client are correct in the connection attempt.
Usually ports 22 and 830 are enabled
Additional ports or different ports can actually be used
If TCP port 830 is blocked by a firewall or other security policy, NETCONF can also run on port 22 (if enabled in the SSH server configuration).
Check the Server Log Activity
If a 'connection refused' error is received then the server is not listening on that port. No log entries for the failed connection will be created in this case.
If no netconfd-pro log activity occurs when --log-level
is set to debug2 or higher, then the SSH server is
most likely not invoking /usr/sbin/netconfd-subsystem-pro
for various reasons. The NETCONF server or yp-shell session
is never getting the session started.
Check the activity in the SSH server log files to determine if the SSH session is getting handled correctly:
Connection failures can usually be found in the
/var/log/auth.logfile.SSH server activity can usually be found in the
/var/log/syslogfile.Some newer systems like Debian 13 require the journalctl command to view the system log files. E.g.:
sudo journalctl -u ssh.service
An example of a SSH connection failure in the log may appear in 'auth.log'
Aug 12 14:32:33 andy-i9-homedev sshd[1752789]: Invalid user fred from 127.0.0.1 port 52218
Aug 12 14:32:38 andy-i9-homedev sshd[1752789]: pam_unix(sshd:auth): check pass; user unknown
Aug 12 14:32:38 andy-i9-homedev sshd[1752789]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=127.0.0.1
Aug 12 14:32:41 andy-i9-homedev sshd[1752789]: Failed password for invalid user fred from 127.0.0.1 port 52218 ssh2
Aug 12 14:32:43 andy-i9-homedev sshd[1752789]: Connection closed by invalid user fred 127.0.0.1 port 52218 [preauth]
An example of a successful SSH connection may appear in 'auth.log':
Aug 12 14:37:40 andy-i9-homedev sshd[1753016]: Accepted password for admin1 from 127.0.0.1 port 40726 ssh2
Aug 12 14:37:40 andy-i9-homedev sshd[1753016]: pam_unix(sshd:session): session opened for user admin1(uid=1002) by (uid=0)
Aug 12 14:37:40 andy-i9-homedev systemd-logind[853]: New session 3019 of user admin1.
Aug 12 14:37:40 andy-i9-homedev systemd: pam_unix(systemd-user:session): session opened for user admin1(uid=1002) by (uid=0)
The 'syslog' file will also have an entry for the successful SSH connection. Example:
Aug 12 14:37:40 andy-i9-homedev systemd[1]: Started Session 3019 of User admin1.
Check the SSH Server Config
Check if the correct ports are configured for the SSH server.
Example 'Port' lines in sshd_config:
Port 22
Port 830
- If the correct ports are set then make sure the netconf
subsystem is invoked correctly. The exact line should appear in the ssd_config file:
Check the SSH server configuration, usually /etc/ssh/sshd_config
Subsystem netconf /usr/sbin/netconf-subsystem-pro
Check Local SSH Connection
If the sshd_config file is correct, make sure the SSH server is running, by using the Linux 'ssh' command to connect to the server.
From the same host as the server, the following command should work if 'Port 22' is enabled in the sshd_config file. Use a different port number if needed with the -p option.
ssh localhost
If the SSH server is running and OK then a terminal session should be established. Use 'exit' to terminate the SSH session.
Check Remote SSH Connection
If the SSH server is working for local terminal sessions then test if it is working for remote sessions
ssh admin1@192.168.1.10
If the SSH server is running and OK then a terminal session should be established. Use 'exit' to terminate the SSH session.
Check the 'netconf' subsystem
If the SSH server is accepting plain terminal sessions correctly, then check if the 'ssh' program connects to the 'netconf' subsystem from a local session:
The following command uses the default SSH port (usually 22):
ssh -s user@ipaddress netconf
To test the NETCONF SSH subsystem on port 830:
ssh -s -p 830 localhost netconf
If the NETCONF server is working properly, then a 'hello' message will be sent by the server, and it will be waiting for the client to send its 'hello' message.
If the NETCONF subsystem test succeeds but client sessions are dropped, check the server log for access-denied or protocol not enabled messages. Session admission controls and protocol enablement parameters include:
Example Server Hello:
<?xml version="1.0" encoding="UTF-8"?>
<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<capabilities>
<capability>urn:ietf:params:netconf:base:1.0</capability>
<capability>urn:ietf:params:netconf:base:1.1</capability>
<!-- Most capability elements removed for brevity -->
</capabilities>
<session-id>7</session-id>
</hello>]]>]]>
Note
If the SSH server is not starting a NETCONF session but it is accepting the SSH session, then the NETCONF subsystem program needs to be checked.
Refer to the Checking the NETCONF Subsystem section for more details.
TLS Connection Issues
The NETCONF Over TLS feature uses the OpenSSL library to directly handle incoming client sessions. The thin client used by SSH is not used for this protocol.
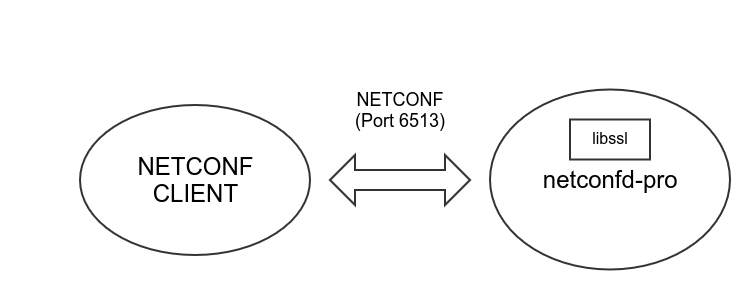
If there is no 'debug' log activity in the netconfd-pro program when the client session is attempted, then the session request is not reaching the server. If there is log activity related to the client session, then check the Check Server Restricting New Sessions section.
Check the TLS Configuration
The --with-netconf-tls parameter must be set to 'true' to use this protocol.
Make sure the --netconf-tls-address and --netconf-tls-port settings match the values used in the client connection attempt
Check the TLS Configuration section to examine the available CLI parameters for this protocol.
Set the --tls-debug parameter to 'true' to debug connection issues
Refer to the Configure TLS section of the YumaPro Installation Guide to setup the client and server X.509 certificates. This step must be done correctly for a NETCONF over TLS session to be accepted.
Example Server Config File to Enable NETCONF over TLS
This is just an example. A real config file will have more settings and may not use all the settings shown here:
netconfd-pro {
with-netconf-tls true
netconf-tls-certificate /home/andy/certs/server.crt
netconf-tls-key /home/andy/certs/server.key
cert-usermap admin1@68:E5:71:6C:C9:8D:33:F2:DC:01:43:F8:E8:8B:CB:3D:BD:9C:2E:2F
}
Example yangcli-pro Config File to Enable NETCONF over TLS
This is just an example. A real config file will have more settings and may not use all the settings shown here:
yangcli-pro {
ssl-certificate ~/certs/client.crt
ssl-key ~/certs/client.key
message-indent 1
use-rawxml true
}
Check the Client Certificate
If the Client Certificate is rejected, then the following log error message may appear in the server log when the client session attempt is made:
agt_openssl: Got other error during SSL handshake, status:-1, err:1
agt_openssl: SSL_accept failed
Example connect command if the yangcli-pro is used:
connect user=admin1 no-password server=localhost transport=tls
Example TLS Connect Failure
If the --log-level is set to 'debug4' then the following example shows how a client verify fail error may appear:
Connect attempt with following parameters:
connect {
user admin1
server localhost
no-password
transport tls
timeout 30
public-key $HOME/.ssh/id_rsa.pub
private-key $HOME/.ssh/id_rsa
ssl-fallback-ok true
ssl-certificate ~/certs/client.crt
ssl-key ~/certs/client.key
ssl-trust-store $HOME/.ssl/trust-store.pem
ncport 830
}
ses_msg: new out buff 0x55c927b855d0 for s 0
Starting NETCONF session for admin1 on localhost over TLS on port 6513
OpenSSL verify callback
Subject: /C=ca/ST=ca/L=ca/O=ca/CN=ca
Issuer: /C=ca/ST=ca/L=ca/O=ca/CN=ca
depth: 1
err: 0
preverify: 1
return: 1
OpenSSL verify callback
Subject: /C=rc/ST=rc/L=rc/O=rc/CN=restconf
Issuer: /C=ca/ST=ca/L=ca/O=ca/CN=ca
depth: 0
err: 10
preverify: 0
return: 0
Error: BIO_do_connect failed
[library name]: SSL routines
[function name]: OPENSSL_internal
[reason string]: certificate verify failed
Error: failed to establish secure connection with server (localhost:6513)
Check the Cert to User Map Settings
If the Client and Server are both accepting the certificates from the other peer, then the user-name assignment for the session needs to be checked.
There are generally 2 ways the user-name can be assigned to a NETCONF over TLS or RESTCONF over TLS session:
Derive a user-name from the SAN in the certificate
Find a cert-usermap entry that matches the fingerprint of the client certificate
The OpenSSL internal APIs will authenticate the client certificate and the client CA certificate.
If the certificate is not accepted then the session will be dropped
If the certificate is accepted then the client user identity is derived from the certificate. This is only possible if a SAN is properly configured. See the Generating Certificates with a SAN section for details.
If no SAN is present then the server will look for a cert to usermap entry, to assign a user-name to the session.
the --cert-usermap CLI parameter can be used to create static mappings at boot-time
the yumaworks-cert-usermap.yang module can be used to manage dynamic mappings at run-time
In a DEBUG=1 build, the --cert-default-user parameter can be used to assign a user-name if none is derived.
In a non-DEBUG build, the session will be dropped if no user-name is assigned to the session.
Example Server Log if Cert to Usermap Entry Found
agt_openssl: enter verify_callback
Certificate details:
Subject: /C=ca/ST=ca/L=ca/O=ca/CN=ca
Issuer: /C=ca/ST=ca/L=ca/O=ca/CN=ca
depth: 1
err: 0
errstr: ok
preverify: 1
return: 1
agt_openssl: Checking digest: 21:80:9E:4F:FA:76:D9:03:3F:03:E1:8A:34:DD:AF:21:00:CE:05:AE
Checking --cert-usermap param 1
agt_openssl: No username found
agt_openssl: exit verify_callback
agt_openssl: enter verify_callback
Certificate details:
Subject: /C=cl/ST=cl/L=cl/O=cl/CN=client.com
Issuer: /C=ca/ST=ca/L=ca/O=ca/CN=ca
depth: 0
err: 0
errstr: ok
preverify: 1
return: 1
agt_openssl: Checking digest: D8:F4:90:DE:45:75:F5:04:C8:A5:7E:D1:13:4E:21:9A:F2:0C:EC:F4
Checking --cert-usermap param 1
Got certmap type (1) specified
Found --user-certmap in entry 1 user=admin1
agt_openssl: exit verify_callback
NETCONF Over Raw TCP (Debug Only)
The server supports a debug mode in which NETCONF sessions can be established over a raw TCP socket instead of the normal SSH or TLS transport protocols.
For normal transport setup, refer to Configure SSH and Configure TLS.
Warning
This mode does not provide transport security and is intended for debugging only.
This mode is useful for troubleshooting NETCONF message handling without involving an SSH daemon or TLS certificate setup. The "tcp-ncx" transport is a YumaPro debug transport and is not a standard NETCONF transport defined by the NETCONF RFCs.
To enable this mode, set --socket-type to "tcp". The --socket-address and --socket-port parameters can also be set if the default (0.0.0.0:2023) is not desired.
Example server command:
netconfd-pro --socket-type=tcp --socket-address=192.168.0.10
To connect from yangcli-pro, set the transport to "tcp-ncx".
Example command in a yangcli-pro session:
connect transport=tcp-ncx user=admin password=password1 server=192.168.0.10
RESTCONF Connection Issues
The RESTCONF protocol is not handled directly by netconfd-pro. Instead a WEB server must be installed and configured to invoke the 'thin client' using the FastCGI interface.
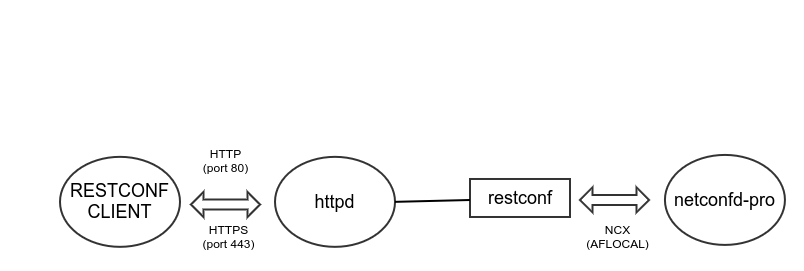
Usually the thin client program is installed
as /usr/sbin/restconf, and it is invoked
when a client request is processed by the WEB server.
RESTCONF does not actually have sessions like NETCONF:
Each WEB request causes a new session request to the NCX socket.
A separate RESTCONF session within netconfd-pro is used for each WEB request.
To debug RESTCONF sessions:
Confirm the WEB server is working correctly
Confirm the 'restconf' thin client program is working correctly
Confirm the session is accepted by netconfd-pro
Check the RESTCONF CLI Parameters
Make sure the RESTCONF CLI parameters are correct:
The --with-restconf parameter must be set to 'true'. This is the default value.
If the server is built from source, then the WITH_RESTCONF=1 compiler flag must be used.
Make sure a WEB server has been setup correctly, as described in the RESTCONF Installation section.
Additional CLI parameters may be used:
Check the RESTCONF WEB Server
If there is no 'debug' log activity in the netconfd-pro process when the client session is attempted then the WEB request from the client is not getting to the netconfd-pro process.
Make sure the WEB server that is supposed to invoke the 'restconf' subsystem is running and is configured properly.
[TBD]
Check the RESTCONF Subsystem
If the WEB server is working properly then the FastCGI program called 'restconf' is invoked from the WEB server.
This program gathers the RESTCONF request parameters from the environment variables passed from the WEB server.
A NCX session is then started with the netconfd-pro process.
The session lasts for the duration of the message.
Refer to the Checking the NETCONF Subsystem section for details on checking the subsystem log files.
Check the RESTCONF Server Log Activity
If there is log activity related to the client session, then check the Check Server Restricting New Sessions section.
Check the RESTCONF User Name
If the REMOTE_USER environment variable is set correctly, then this
value should be passed to the netconfd-pro process as the user name for the session.
If this variable is missing then the following message should be present in the subsys log file:
Error: Missing REMOTE_USER
If no user name is found then the string restconf will be used as
the user-name.
SNMP Usage Troubleshooting
SNMP support is provided by the yp-snmp subsystem. Net-SNMP version 5.7.3 or later is required.
For full installation, configuration, build, setup, and usage examples, refer to the YumaPro yp-snmp Manual and the Building SNMP support section.
If SNMP support is required, install a YumaPro package that includes SNMP support (for example, yumapro-snmp).
If netconfd-pro is built from source, the WITH_SNMP=1 make flag is required to build SNMP support.
SNMP must be enabled in netconfd-pro with --with-snmp=true.
Net-SNMP provides the SNMP libraries and tools used by yp-snmp. The snmpd and snmptrapd programs are Net-SNMP tools used for configuration and troubleshooting. If netconfd-pro is configured to listen on the standard SNMP agent port (UDP port 161), make sure snmpd is not running on the same port.
The server must be started with sufficient privileges to bind to the standard SNMP agent port (UDP port 161, a well-known port used by SNMP).
If SNMP requests do not work as expected, common checks include:
When SNMP is enabled, the server log typically includes messages similar to:
SNMP initializing master ... NET-SNMP version ...
If these messages are not present, confirm that Net-SNMP is installed, that --with-snmp=true is set, and that the server build supports SNMP (for example, an SNMP-capable package install or a source build with WITH_SNMP=1).
If snmpget (or similar) reports no response from the host, confirm that firewall rules allow UDP port 161 and that the correct host/port are being used:
snmpget -v 2c -c public localhost 1.3.6.1.2.1.2.1.0
no response from local host
If an SNMP request fails with "No security name found", confirm that Net-SNMP is installed and that an snmpd.conf file exists and matches the request configuration.
The security name is derived from the community string (SNMPv1/v2c) or the user name (SNMPv3), depending on the request.
Example command:
snmpget -v 2c -c public localhost 1.3.6.1.2.1.2.1.0
Example output:
Error: agt_ypsnmp_sec No security name found
Net-SNMP uses two configuration files to control SNMP operation:
/var/net-snmp/snmpd.confThis file contains SNMPv3 specific configuration (for example, allowed user names and passwords).
/usr/local/share/snmp/snmpd.confThis file contains generic SNMP configuration, including SNMPv1 and SNMPv2c community strings used for authentication. If not found in the locations above, the configuration file may be found in
/etc/yumapro/snmpd.conf. Move this file to one of the active locations to make the configuration effective.
The snmpd.conf location is OS dependent and Net-SNMP installation dependent.
netconfd-pro implements NACM (NETCONF Access Control Model). Since NACM provides authorization, VACM must be disabled when processing SNMPv3 requests. Refer to SNMP Security and SNMPv3 for details.
SNMP SET operations are not supported.
The yp-snmp subsystem is read-only. Use NETCONF or RESTCONF edit operations to modify configuration data.
Net-SNMP updates are not provided by YumaWorks as part of YumaPro. Install and update Net-SNMP using the operating system package manager or a local source build.
If the server is started successfully and Net-SNMP logging is present, but SNMP requests return "No Such Object", confirm that the expected MIB-derived YANG modules are loaded and that the request is reaching the intended agent:
Example command:
snmpget -v 2c -c public localhost 1.3.6.1.2.1.2.1.0
Example output:
IF-MIB::ifNumber.0 = No Such Object available on this agent at this OID
Also make sure the snmpd daemon is not running in parallel and already bound to UDP port 161. If the server log indicates "Address already in use", stop snmpd and restart netconfd-pro:
Example snmpd.conf snippet:
... rocommunity public ...
sudo service snmpd stop
If additional Net-SNMP debug output is needed, enable Net-SNMP debug logging in snmpd.conf:
[snmp] doDebugging 1 debugTokens netsnmp_udp_getSecName,sess_process_packet,netsnmp_udp,read_config
Example server log snippet:
netsnmp_udpbase: set IP_PKTINFO netsnmp_udpbase: binding socket: 5 to UDP: [0.0.0.0]:0->[0.0.0.0]:161 netsnmp_udpbase: failed to bind for clientaddr: 98 Address already in use netsnmp_udp6: open local UDP/IPv6: [::]:161 netsnmp_udpbase: binding socket: 5 to UDP/IPv6: [::]:161
Checking the NETCONF Subsystem
There are some programs which are used as a 'thin client' to connect to the netconfd-pro process. This is usually done with an 'AFLOCAL' socket.
The following programs use this thin client to connect to the netconfd-pro process.
netconf-subsystem-pro
restconf
The netconf-subsystem-pro thin client is invoked by sshd for NETCONF over SSH sessions, using the "Subsystem netconf" setting in the sshd_config file.
The special 'NCX' socket is used by this thin client.
The --socket-type, --socket-address, and --socket-port parameters will affect how the netconfd-pro listens for 'NCX Connect' messages.
Normally the AFLOCAL socket
/tmp/ncxserver.sockis used.
/tmp/subsys-err Log Files
Warning
Enabling subsystem logging will impact server performance and potentially use significant disk space.
Only use as a temporary measure during debugging.
With trace level 3, these log files are preserved after the session ends and must be deleted manually from the /tmp directory.
These log files may contain sensitive data (including decrypted protocol payloads) and should be handled accordingly.
The netconf-subsystem-pro program is also referred to as netconf-system-pro in some KB articles. A log file is not created by default.
The thin client program can produce a log file. This can be examined to determine if any settings or errors are occurring in this program.
The log files must be enabled, 1 of 2 ways:
For source builds, compile the subsystem sources with DEBUG=1 and DEBUG2=1.
Invoke the subsystem with the '-t' option. This can be done for SSH by modifying the
/etc/ssh/sshd_configfile.Existing line to invoke subsystem
Subsystem netconf /usr/sbin/netconf-subsystem-pro
Change line to enable trace level 3 (highest)
Subsystem netconf /usr/sbin/netconf-subsystem-pro -t 3
The netconf-subsystem-pro program also supports additional options that can be used in the sshd_config Subsystem line:
netconf-subsystem-pro
netconf-subsystem-pro -f file | -filename file
netconf-subsystem-pro -t level | -trace level
netconf-subsystem-pro -p proto | -protocol proto
If trace level 3 is used, a separate trace file is generated for each session and preserved after the session ends.
If the '-f' option is not used, the default trace file location is under /tmp. The log file names have a specific format, using the process PID number to make each file name unique:
/tmp/subsys-err.PPPPPP.log
Where PPPPPP is the PID number.
Example Log File Name:
/tmp/subsys-err.304840.log
Example Log File If netconfd-pro Not Running
If the SSH server is running but the netconfd-pro process cannot be reached, then the thin client program will fail, and the log file will usually indicate why the session was 'shut by remote peer'.
*** New NETCONF Session Started ***
traceLevel 3
content_len -1
Got USER variable 'admin1'
Got SSH_CONNECTION variable '127.0.0.1 35182 127.0.0.1 830'
ERROR: init_subsys(): NCX Socket Connect failed (errno=No such file or directory) FD:4
ERROR: return 315
Example Log File If netconfd-pro Starts OK
If the SSH server is running and the netconfd-pro process can be reached, then the thin client program will not fail, and the log file will contain the entire session activity.
The start of the log file may look as follows:
*** New NETCONF Session Started ***
traceLevel 3
content_len -1
Got USER variable 'admin1'
Got SSH_CONNECTION variable '127.0.0.1 43638 127.0.0.1 830'
DEBUG: init_subsys(): NCX Socket Connected on FD: 4
DEBUG: starting io_loop()
DEBUG: io_loop: about to call select
DEBUG: read STDIN
DEBUG: do_read: OK (250)
DEBUG: io_loop: send to NCXSOCK (250)
DEBUG: io_loop(): Sending buff
Check Server Restricting New Sessions
There are CLI parameters which may affect how sessions are processed, that can cause a 'NCX Connect' request to be denied.
Allowed Users List
The --allowed-user leaf-list parameter allows the specific user names to be configured.
If this list is empty, then any user name will be accepted
If this list is not empty then only user names in this list will be allowed to start a client session.
This does not affect subsystem sessions, only client sessions.
The server will simply terminate the session. The log file will indicate that the allowed-user test failed:
agt_connect: got node for session 4
agt_connect: got valid version attr
agt_connect: got valid magic attr
agt_connect: transport='ssh'
agt_connect: protocol='netconf'
agt_connect: got valid port attr
agt: allowed-user check failed for 'admin1'
agt_connect error: user 'admin1' not in allowed-user list
agt_connect error (access denied)
dropping session 4
The subsys log file may appear as follows when the NCX Connect succeeds but the server immediately drops the session:
*** New NETCONF Session Started ***
traceLevel 3
content_len -1
Got USER variable 'admin1'
Got SSH_CONNECTION variable '127.0.0.1 40400 127.0.0.1 830'
DEBUG: init_subsys(): NCX Socket Connected on FD: 4
DEBUG: starting io_loop()
DEBUG: io_loop: about to call select
DEBUG: read STDIN
DEBUG: do_read: OK (250)
DEBUG: io_loop: send to NCXSOCK (250)
DEBUG: io_loop(): Sending buff
<?xml version="1.0" encoding="UTF-8"?><hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"><capabilities><capability>urn:ietf:params:netconf:base:1. 0</capability><capability>urn:ietf:params:netconf:base:1.1</capability></capabilities></hello>]]>]]
DEBUG: io_loop: about to call select
DEBUG: read NCXSOCK
INFO: do_read(): closed connection
INFO: io_loop(): exited OK
OK return
Max Sessions Limit
The maximum number of concurrent client sessions is limited by the --max-sessions parameter. The default value is 8.
After this number of client sessions is already active, then new client session requests will be rejected
Sessions from subsystems are not affected, only client sessions
yp-shell sessions are constrained by the --max-cli-sessions parameter as well.
The server log file will contain a message about the dropped session. Example:
Enter agt_ses_new_session for transport 'netconf-ssh', fd 7
agt_ses: Drop session because max-sessions reached
agt_ncxserver: new session failed (7)
YP-HA Waiting Role
If the server is running with --ha-enabled='true' then it is possible the server is waiting for its HA role and is rejecting new client sessions.
In this case the server will generate a log entry that says 'init2 not done'.
An example of the server log may appear as follows in this case:
agt_top: got node
agt_top: start dispatch yuma-ncx:ncx-connect
agt_connect: got node for session 7
agt_connect: got valid version attr
agt_connect: got valid magic attr
agt_connect: transport='ssh'
agt_connect: protocol='netconf'
agt_connect: got valid port attr
agt: skip allowed-user check for 'andy'; not configured
agt_connect error: init2 not done
agt_connect error (access denied)
dropping session 7
Session Behavior Issues
Note
Symptom: Client session starts but is not working correctly
Unexpected Error Responses
If the session is working correctly, then requests will cause a reply from the server. If the server rejects an RPC request then it will respond with an error:
NETCONF: <rpc-error> response
RESTCONF: <error> response
CLI: <rpc-error> log message
Check the Session Timeout Issues section if the response is not getting received in a normal amount of time.
Wrong Config State Error
The error message wrong config state is used by the
following error-tag:
ERR_NCX_NO_ACCESS_STATE= 302
Summary:
This error indicates that the server datastores are not ready or not accessible at the moment.
Common symptoms:
Client connection succeeds, but datastore content is not accessible.
The yangcli-pro
show sessionoutput indicates the YANG library URI is not found.A <get> or <get-config> operation fails with
wrong config state.
There are two different causes for receiving this error:
Waiting for SIL-SA Bundle Load
Operation is a retrieval or edit operation
Error number 302 returned
Any attempt to read or write any datastore data will fail if the server has not loaded the datastores yet.
This usually means there is a --bundle parameter used and no SIL library was found for the bundle.
The server does not know the modules used in the bundle until the bundle is actually loaded.
The datastores cannot be loaded yet in case there are any data nodes from missing bundles.
The server is waiting for a sil-sa-app process to register with the server and register for the missing bundle(s).
If this condition occurs, the server log may include lines similar to:
Got number file value '2577'
agt: Waiting SIL-SA: skipping load_running_config
ncx: Adding Mod load callback to slot 1
ncx: Adding Mod unload callback to slot 0
netconfd-pro init OK, ready for sessions
Even when the log indicates "ready for sessions", datastore-backed operations can still fail until datastore readiness is complete. RPC operations that do not access datastores can still function.
For this startup mode, set --wait-datastore-ready=true so client sessions are rejected until the datastore is ready.
Example server command:
netconfd-pro --wait-datastore-ready=true --bundle=mybundle
With this setting, SSH or TLS transport may connect, but the NETCONF session is closed immediately if datastores are not ready.
Example command in a yangcli-pro session:
run connect
Example output:
ses: session 3 shut by remote peer
yangcli-pro: Start session failed for user andy on localhost (operation failed)
Unlock a Datastore that is Not Locked
Operation is <unlock>
Error 302 returned
Any attempt to unlock a datastore that is already unlocked will fail with a '302' error-number.
Example RPC Error:
<rpc-reply message-id="1" xmlns:ncx="http://netconfcentral.org/ns/yuma-ncx"
xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<rpc-error>
<error-type>protocol</error-type>
<error-tag>operation-failed</error-tag>
<error-severity>error</error-severity>
<error-app-tag>no-access</error-app-tag>
<error-message xml:lang="en">wrong config state</error-message>
<error-info>
<error-number>302</error-number>
</error-info>
</rpc-error>
</rpc-reply>
No Access Error
The error message access denied is used by the
following error-tag:
ERR_NCX_ACCESS_DENIED= 267
Example RPC Error:
<rpc-reply message-id="3" xmlns:ncx="http://netconfcentral.org/ns/yuma-ncx"
xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<rpc-error>
<error-type>protocol</error-type>
<error-tag>access-denied</error-tag>
<error-severity>error</error-severity>
<error-app-tag>no-access</error-app-tag>
<error-message xml:lang="en">access denied</error-message>
<error-info>
<error-number>267</error-number>
</error-info>
</rpc-error>
</rpc-reply>
This error is commonly caused by NACM access control rules. NACM is enabled by default and the --access-control parameter defaults to "enforcing". In this mode, write access is denied unless an explicit NACM rule permits the operation.
To temporarily disable access control enforcement during evaluation or debugging, set --access-control=off. Use this setting with care.
To allow full access for a specific user while configuring NACM, configure that user as a --superuser.
For more details:
Refer to the Access Control section for details on NACM configuration.
Refer to the NACM Access Troubleshooting section for help identifying NACM mis-configuration errors.
Missing Parameter Error
The error message "missing parameter" is used with the following error-tag:
"missing-element" (error-number 233)
This error commonly indicates that a mandatory leaf is not present when an entry is created or edited.
The following example uses the ietf-interfaces module. Start the server with the interface module and the module that defines the interface type identities:
netconfd-pro --module=ietf-interfaces --module=iana-if-type
Example commands in a yangcli-pro session to create an interface entry without the mandatory "type" leaf:
/interfaces/interface/name value=vlan1
commit
Example error reply:
<rpc-reply message-id="3"
xmlns:if="urn:ietf:params:xml:ns:yang:ietf-interfaces"
xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<rpc-error>
<error-type>application</error-type>
<error-tag>missing-element</error-tag>
<error-severity>error</error-severity>
<error-app-tag>data-incomplete</error-app-tag>
<error-path>/if:interfaces/if:interface[if:name="vlan1"]/if:type</error-path>
<error-message xml:lang="en">missing parameter</error-message>
<error-info>
<bad-element xmlns:if="urn:ietf:params:xml:ns:yang:ietf-interfaces">if:type</bad-element>
<error-number>233</error-number>
</error-info>
</rpc-error>
</rpc-reply>
The error is generated during YANG datastore validation, when the server checks mandatory nodes for each instance.
Example validation log snippet:
instance_check 'ietf-interfaces:type' against 'ietf-interfaces:interface'
(cnt=0, min=1, max=1)
agt_record_error for session 3:
The "type" leaf is mandatory in the ietf-interfaces data model:
leaf type {
type identityref {
base interface-type;
}
mandatory true;
description
"The type of the interface.
When an interface entry is created, a server MAY
initialize the type leaf with a valid value, e.g., if it
is possible to derive the type from the name of the
interface.
If a client tries to set the type of an interface to a
value that can never be used by the system, e.g., if the
type is not supported or if the type does not match the
name of the interface, the server MUST reject the request.
A NETCONF server MUST reply with an rpc-error with the
error-tag 'invalid-value' in this case.";
reference
"RFC 2863: The Interfaces Group MIB - ifType";
}
Provide the missing mandatory leaf before commit.
Set the value in one command:
create /interfaces/interface[name='vlan1']/type value='ianaift:l2vlan'
commit
Or set the key and the mandatory leaf in separate commands:
/interfaces/interface/name value=vlan1
/interfaces/interface/type value='ianaift:l2vlan'
commit
Note that the "type" leaf is an identityref, and the "ianaift:l2vlan" identity is defined in the iana-if-type module.
YANG Library Issues
Augment Problems
If a client has a problem reading the YANG Library information when a session starts, check if the response is rejected because of an 'unknown namespace' or 'unknown element' error. If so, make sure the following CLI parameter settings are used:
--remove-schema-aug-leafs='true'
--with-yanglib-augmentedby='false'
NMDA Not Enabled
Normally, clients attempt to retrieve the non-NMDA '/modules-state' subtree. If the client is attempting to retrieve the NMDA '/yang-library' subtree, and it is not found, make sure the following CLI parameter setting is used:
--with-nmda='true'
Module Not Found
If the client does not have a YANG module specified in the YANG library, then it should attempt to retrieve it with the <get-schema> operation. If this operation fails (e.g., file not found) then the client may not be able to continue with the session.
Make sure all YANG modules needed by a client can be found by the server. Use the --modpath parameter if needed.
Session Timeout Issues
The --timeout parameter used in yangcli-pro sessions has a default value of 30 seconds. For some operations, such as a complex commit on a large datastore, this may not be enough time.
Try a higher timeout value for the request if the server is sending late responses
If the server is single-threaded (i.e. no PTHREADS=1 make flag used) then the server may be busy with another session.
Even if the server is multi-threaded, it is possible for sessions to wait on other sessions. E.g.:
module or bundle is being loaded or unloaded
datastore is being edited
subsystem is initializing
If no other sessions are causing the server to be busy, then the server log activity needs to be checked.
Server Performance Troubleshooting
This section describes how to debug server performance issues with Valgrind, Callgrind, and KCachegrind.
Callgrind uses runtime instrumentation through the Valgrind framework for cache simulation and call-graph generation. Shared libraries and dynamically opened plugins can also be profiled. The data files generated by Callgrind can be loaded in KCachegrind to browse performance results.
The package also includes a command line report tool for callgrind data files. That tool is out of scope for this section.
Performance Tool Installation
Install valgrind, kcachegrind, and graphviz.
Requirements include:
Callgrind (part of Valgrind; supports Linux on x86, amd64, arm7, and other supported platforms)
KCachegrind
KDE libraries and development files (KDE 4.4 or higher)
QCachegrind (included in KCachegrind sources)
Qt4 (4.x) or Qt5
The 'dot' binary (GraphViz) for call-graph views (runtime requirement)
The 'objdump' binary (BinUtils) for annotated machine-code views (runtime requirement)
Example install commands:
sudo apt-get install valgrind kcachegrind graphviz
sudo aptitude install valgrind kcachegrind graphviz
These packages are available in major Linux distributions. On Ubuntu 14.04 or higher, either command above can be used. Graphviz is needed to view call graphs in KCachegrind.
Run Callgrind with netconfd-pro
Start netconfd-pro through Valgrind Callgrind. The server CLI parameters can vary.
General form:
valgrind --tool=callgrind [callgrind options] your-program [program options]
Example:
valgrind --tool=callgrind netconfd-pro module=ietf-interfaces module=iana-if-type log-level=info no-config access-control=off
For additional callgrind option details, refer to the Valgrind callgrind manual.
Run the operation to profile, then shut down the server. After cleanup, output similar to the following is expected:
==7729==
==7729== Events : Ir
==7729== Collected : 175808352
==7729==
==7729== I refs: 175,808,352
The result is stored in a callgrind.out.XXX file, where XXX is the process ID.
ls
callgrind.out.7729
The file can be opened in a text editor, but the raw profile format is typically cryptic. KCachegrind is recommended for analysis.
Example command to open results in KCachegrind:
kcachegrind callgrind.out.7729
KCachegrind can also be started from the desktop program menu and then used to open the profile file.
Review Results in KCachegrind
The callgrind output file can be opened in KCachegrind for interactive analysis.
The main function list shows:
Inclusive cost
Self cost
Source location
After selecting a function, additional views are populated. The upper-right view provides summary information for the selected function.
Common tabs include:
Types: recorded event types
Callers: direct callers
All Callers: full caller chain
Callee Map: call relationship map
Source code: source view when debug symbols are present
Additional function tabs include:
Callees: direct callees
Call Graph: graph from selected function to the end
All Callees: full callee chain
Caller Map: caller-side map
Machine Code: available when profiled with --dump-instr=yes
These views and filters help identify functions that consume too much time or are called too frequently.
Run Valgrind Memcheck with netconfd-pro
This workflow can be used to debug memory corruption and invalid read issues. For more details, refer to: Valgrind Tutorial
General form:
valgrind -v --leak-check=full --show-leak-kinds=all netconfd-pro [server options]
Example:
valgrind -v --leak-check=full --show-leak-kinds=all netconfd-pro module=ietf-interfaces module=iana-if-type log-level=info no-config access-control=off
After starting the server with Valgrind, run the operation that reproduces the memory issue, then stop the server process (for example, Ctrl+C in the same terminal).
Example summary output after shutdown may look as follows:
agt_acm: Clearing context cache
agt_ncx: Start unregister RPC callbacks
agt_not: cleaning stream 'NETCONF'
ncx: Clear Mod load callback (slot 2)
ncx: Clear Mod load callback (slot 1)
agt_nmda: disabled, skipping cleanup phase
ncx: Clear Mod load callback (slot 0)
==3297==
==3297== HEAP SUMMARY:
==3297== in use at exit: 32 bytes in 1 blocks
==3297== total heap usage: 53,254 allocs, 53,253 frees, 90,476,358 bytes allocated
==3297==
==3297== Searching for pointers to 1 not-freed blocks
==3297== Checked 879,624 bytes
==3297==
==3297== 32 bytes in 1 blocks are still reachable in loss record 1 of 1
==3297== at 0x4C31B25: calloc (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==3297== by 0x68A37F4: _dlerror_run (dlerror.c:140)
==3297== by 0x68A3050: dlopen@@GLIBC_2.2.5 (dlopen.c:87)
==3297== by 0x4F207BF: agt_load_sil_code (agt_sil_lib.c:498)
==3297== by 0x4F20227: load_SIL_loadpath (agt_sil_lib.c:301)
==3297== by 0x4F2019F: load_SIL (agt_sil_lib.c:264)
==3297== by 0x4F048C1: agt_init2_ex (agt.c:3815)
==3297== by 0x10AC75: cmn_init (netconfd.c:335)
==3297== by 0x10B188: main (netconfd_main.c:191)
==3297==
==3297== LEAK SUMMARY:
==3297== definitely lost: 0 bytes in 0 blocks
==3297== indirectly lost: 0 bytes in 0 blocks
==3297== possibly lost: 0 bytes in 0 blocks
==3297== still reachable: 32 bytes in 1 blocks
==3297== suppressed: 0 bytes in 0 blocks
==3297==
==3297== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
==3297== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
Interpretation notes:
"still reachable" at exit is usually not treated as a leak error.
"definitely lost" and "indirectly lost" indicate real leaks.
"possibly lost" should be investigated.
Server Memory Leaks Troubleshooting
To run mtrace for memory leak debugging:
Build with normal make flags plus MEMTRACE=1.
Make sure
$HOME/mtracefiledoes not already exist.Run netconfd-pro from $HOME. Do not run other programs (for example, yangcli-pro) from the same directory, or the mtrace file can be overwritten.
Add the following line to '.bashrc' and reload the shell settings:
export MALLOC_TRACE=./mtracefile
source ~/.bashrc
This sets the mtrace output file to the directory where the program is run.
Add the following line to '.bashrc':
ulimit -c unlimited
This enables core-file generation so crash diagnostics are preserved.
Configuration Editing Issues
Note
Symptom: Edit operation is not working correctly
YANG Validation Issues
If the --target parameter is set to candidate, then
the YANG validation 'root-check' is usually done during
the <commit> operation. It may be done during <edit-config>
if the 'test-option' has the value 'test-then-set'.
The YANG Constraints are defined in section 8 of RFC 7950. There are many different errors that may be returned.
The NETCONF Error Responses for YANG-Related Errors are defined in section 16 of RFC 7950. The server follows these requirements for YANG validation errors.
To determine if the <candidate> datastore passes YANG validation, use the <validate> operation.
OpenConfig Pattern Syntax Errors
Some OpenConfig YANG modules use a different pattern syntax than the YANG standard pattern statement rules. This can result in YANG compiler errors or pattern-match behavior that is not expected.
To enable OpenConfig-style pattern checking for module names starting with "openconfig-", use the --with-ocpattern parameter.
The default value is false, so it must be enabled in the command line or the configuration file for tools that process these modules.
Some OpenConfig modules use regular expressions that are not compatible with the YANG pattern rules (which are based on XSD regular expressions). When such patterns are interpreted as YANG patterns, compilation can fail or run-time pattern checks can produce unexpected results.
The following example is a simplified excerpt from OpenConfig inet-types.yang:
typedef ipv4-address {
type string {
pattern '^(([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|' +
'25[0-5])\.){3}([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4]' +
'[0-9]|25[0-5])$';
}
The following example shows an excerpt from ietf-inet-types.yang:
typedef ipv4-address {
type string {
pattern
'(([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\.){3}'
+ '([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])'
+ '(%[\p{N}\p{L}]+)?';
}
To support OpenConfig modules, enable --with-ocpattern. When it is enabled, modules with names starting with "openconfig-" are treated as OpenConfig (POSIX) patterns. All other modules continue to use YANG pattern rules.
The --with-ocpattern parameter can be set in configuration files in
/etc/yumapro:
netconfd-pro.conf
yangcli-pro.conf (yangcli-pro and yp-shell)
yangdump-pro.conf (yangdump-pro and yangdump-sdk)
#### leaf with-ocpattern
#
# If true, then OpenConfig patterns will be checked.
# If the module name starts with the string 'openconfig-'
# then all pattern statements within that module
# are treated as POSIX patterns, not YANG patterns.
# If false, then the pattern statements in all modules
# will be checked as YANG patterns.
#
with-ocpattern true
Required Instance Test Failed
The error message require-instance test failed is used by the
following error-tag:
ERR_NCX_MISSING_INSTANCE= 350
Leafref nodes usually require that the 'pointed-at' instances contain any values used by a 'pointing-at' leaf. Errors can occur different ways:
Attempt to create a 'pointing-at' leaf or leaf-list but none of the 'pointed-at' leaf instances match this value
Attempt to delete or change a 'pointed-at' leaf but at least one of the 'pointing-at' leaf instances match this value, and deleting or changing the leaf would cause that value to be unavailable.
Example YANG:
leaf one {
type string;
}
container top {
leaf two {
type leafref {
path "/one";
}
}
}
The same error is returned for different edit operations
The 'error-path' will indicate a 'pointing-at' leaf or leaf-list, even if the 'pointed-at' leaf is the data node that is being edited
The 'error-tag' will be
data-missingeven if the edit operation is an attempt to delete or change a 'pointed-at' leaf.The default 'error-message' will be
required value instance not foundeven if the edit operation is an attempt to delete or change a 'pointed-at' leaf.
Example RPC Error Reply
<rpc-reply message-id="6"
xmlns:my3="urn:yumaworks:params:xml:ns:yang:mytest3"
xmlns:ncx="http://netconfcentral.org/ns/yuma-ncx"
xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<rpc-error>
<error-type>application</error-type>
<error-tag>data-missing</error-tag>
<error-severity>error</error-severity>
<error-app-tag>instance-required</error-app-tag>
<error-path>/my3:top/my3:two</error-path>
<error-message xml:lang="en">require-instance test failed</error-message>
<error-info>
<error-number>350</error-number>
</error-info>
</rpc-error>
</rpc-reply>
Memory growth during edits
Note
Symptom: During repeated edits (e.g., 200 operations per batch), systemctl status netconfd-pro.service shows increasing Memory. After a service restart, the memory value returns to an initial baseline.
Repeated edit operations (direct edits or RPCs that trigger YANG Patch) can appear to "leak" memory when monitoring systemctl status for netconfd-pro. In many cases, the observed growth is not heap retention but file-backed page cache and related kernel accounting that is charged to the systemd service cgroup.
Why systemctl "Memory" grows
systemctl status reports cgroup MemoryCurrent, which includes page cache and kernel metadata, not just application heap allocations. Since edits/RPCs generate datastore/log I/O, it is normal for Linux to cache recently accessed/written file pages and charge them to the service cgroup. This can increase systemctl "Memory" even when heap allocations are freed correctly.
Why mallinfo2() deltas can mislead
mallinfo2() reports allocator-internal counters and is affected by allocator caching/fragmentation. A "bytes allocated vs bytes freed" delta inside a short code region does not directly map to process RSS or to kernel-reported memory usage. Freed blocks may be retained in allocator caches, and memory may be returned later (or not returned to the OS at all), even though it is reusable by the process.
Measurement procedure
This procedure determines whether the observed netconfd-pro memory growth is driven by heap/anonymous memory retention (potential leak) or by file-backed page cache due to logging and datastore persistence.
Test method:
Restart netconfd-pro to establish a clean baseline.
Establish one client session.
Run N identical operations (e.g., N RPC invocations) that update the same target leaf value.
Capture the memory snapshot.
Repeat steps 3-4 and compare trends.
The most important indicators are:
Heap-like growth: anon (cgroup) and Private_Dirty (process) increase steadily.
I/O/page-cache growth: file/inactive_file increase while anon and Private_Dirty remain stable.
Run the following commands to collect data:
PID=$(systemctl show -p MainPID --value netconfd-pro.service)
CG=$(systemctl show -p ControlGroup --value netconfd-pro.service)
echo "=== cgroup total (systemctl MemoryCurrent) ==="
cat /sys/fs/cgroup"$CG"/memory.current
echo "=== cgroup breakdown (anon vs file cache) ==="
egrep '^(anon|file|inactive_file|slab)\b' /sys/fs/cgroup"$CG"/memory.stat
echo "=== process memory rollup (best heap signal: Private_Dirty) ==="
egrep 'Rss:|Pss:|Private_Dirty:' /proc/$PID/smaps_rollup
echo "=== cache cleanliness (dirty/writeback should be near 0 for clean cache) ==="
egrep '^(file_dirty|file_writeback)\b' /sys/fs/cgroup"$CG"/memory.stat
echo "=== files being written (logs/datastore) ==="
sudo lsof -p "$PID" | egrep -i 'server\.log|audit\.log|sysrepo|startup|running|\.db'
Interpretation guide
Expected behavior - I/O-driven page cache growth (most common)
memory.current increases
memory.stat shows file / inactive_file increases significantly
memory.stat shows anon remains roughly stable
/proc/<PID>/smaps_rollup shows Private_Dirty roughly stable
file_dirty=0 and file_writeback=0 (clean reclaimable cache)
Page cache is accumulating due to file I/O (logs, datastore persistence). If anon and Private_Dirty remain stable while file/inactive_file increases, the growth is consistent with page-cache from I/O/logging, not leaked heap pointers.
Suspicious behavior - possible heap retention
memory.stat shows anon increasing steadily per batch
/proc/<PID>/smaps_rollup shows increasing Private_Dirty and/or RSS
Growth correlates with operation count even when editing the same node repeatedly
SIL or SIL-SA Callback Issues
Note
Symptom: SIL Callback for RPC, Action, EDIT, or GET2 is not working correctly
Debugging SIL-SA Code
SIL-SA code typically runs in a separate subsystem process. Debugging is done by attaching a debugger to the subsystem process, or by running the subsystem program under a debugger.
The sil-sa-app test program can be used to start a subsystem process
and register it with the server. Debugging can focus on the sil-sa-app entry
point source file, main.c, in the sil-sa-app/src directory.
This is commonly located in /usr/local/share/yumapro/src/sil-sa-app/src.
The sil-sa-app program only loads SIL-SA libraries found via $YUMAPRO_RUNPATH, and the server must load the corresponding YANG modules for those libraries.
For example, a SIL-SA library for foo.yang is named libfoo_sa.so.
Start the server and disable the subsystem timeout. The default value for --subsys-timeout is 30 seconds. A value of 0 disables the timeout:
netconfd-pro --module=foo --subsys-timeout=0
In another shell, start sil-sa-app with debug logging:
sil-sa-app --log-level=debug2 --subsys-id=subsys1
Callback Crashes With Garbage or NULL Pointer
If the server invokes the callback function, and parameters or fields within a struct are NULL or some invalid value, then could be a build problem.
Make sure all old libraries and binary code are removed.
Rebuild all code from sources or binary libraries
Add the DEBUG=1 make flag to enable symbolic debugging
Make sure the correct SIL or SIL-SA Compiler Flags are used for your binary package
Callback Crashes When a VAL macro is Used
The val_value_t struct is often used within YANG instrumentation code.
Check the Base Type
The 'btyp' is a critical field that determines which variant of the v_
union is used. If the wrong macro is used for the basetype, then
the code is very likely to crash at that point.
ncx_btype_t btyp = VAL_TYPE(val);
Example: Use 'uint32' macro but the btyp is really NCX_BT_STRING
// WRONG!!! CAUSES CRASH!!!
uint32 num = VAL_UINT32(val);
// BETTER TO CHECK THE TYPE!!!
if (VAL_TYPE(val) == NCX_BT_UINT32) {
uint32 num = VAL_UINT32(val);
}
Check the Leafref Type
The 'btyp' for a leafref node starts out as NCX_BT_LEAFREF.
If the 'btyp' is set to this value then the
VAL_STRING()macro must be used to access the preliminary value.To access the real value in this case, the 'val_convert_leafref' function can be used
if (VAL_TYPE(val) == NCX_BT_LEAFREF) {
val_value_t *realval = val_convert_leafref(val);
// ...
}
See val_convert_leafref() for details.
Reporting Suspected Bugs
If an issue appears to be a defect, submit a support ticket or send an email with enough detail to reproduce the behavior.
Include the following information in the Description field:
YumaPro SDK version (e.g., 25.10-10).
Use the latest available version when possible to avoid issues already fixed and to include improvements in newer releases.
For packaged tools, use --version.
For source builds, use the source tarball version.
Affected tool (client, server, compiler, code generation, etc.).
If the tool is unclear, note that.
Problem description:
Protocol, operation, parameters, expected behavior, and actual behavior.
Be specific: what protocol, what operation, and what parameter.
Describe the expected behavior and what happened instead.
Reproduction steps with exact commands.
Include the yangcli-pro commands for NETCONF issues.
Include the full curl command and any input/output files for RESTCONF issues.
Include the complete command line (including script name) for SIL or SIL-SA generation issues (e.g., make_sil_bundle).
Provide all YANG modules involved.
Complete server and/or client logs captured from program start.
Set --log-level to debug4 on the command line.
Set a log file with --log (e.g., --log=file.txt --log-level=debug4).
Include the full log from program start even when log snippets are provided.
Set --log-level on the command line, not in the .conf file.
Include SIL-SA or DB-API subsystem logs when relevant.
All relevant YANG modules (e.g., modules.tar or a list of module names and revisions).
Create a small test module that can demonstrate the problem when possible.
Provide YANG modules even for open-source modules to ensure matching revisions, or provide a complete list of module names and revisions.
Include imported modules and any bundle contents.
Configuration file or command line parameters used (e.g., netconfd-pro.conf).
If unavailable, include a log showing the expanded CLI parameters at startup.
Additional relevant data.
XML data files used in yangcli-pro or other scripts.
Server startup-cfg.xml file.
Minimal test modules when possible.
Screenshots only when text output is unavailable (text files preferred).
Collecting Support Data
The <get-support-save> command collects most of the required data for Technical Support, including:
bundles
capabilities
configuration data
datastores
modules
server name and version
sessions
SILs
server system
The <get-support-save> command is available from a yangcli-pro session connected to the netconfd-pro server. Example:
@~/work/example-bug.xml = get-support-save
Attach the resulting XML file to the FreshDesk ticket using "Add note" and the paper clip icon, then include the reproduction steps in the note.
Reproduction Steps (Example)
Start the server:
netconfd-pro --log-level=debug4 --param1 --param2 --module=xyz.yang --log=bug-output.log
Start yangcli-pro:
yangcli-pro user@srv1
Then connect:
connect server=srv1 user=fred password=pw1
Run the commands that trigger the issue:
command1 param1=xyz param2=abc
command2 param3=klm
Describe the observed symptom after the final command.
Additional Attachments
Attach relevant log files and note the "message-id" for the failing "<rpc>" and "<rpc-reply>" entries. Example:
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply message-id="3"
xmlns:ncx="http://netconfcentral.org/ns/yuma-ncx"
ncx:last-modified="2017-10-04T00:51:19Z" ncx:etag="57332"
xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<data>
Workarounds
If a workaround exists, include it in the ticket. Example:
If command2 is run before command1, the issue does not occur.